One-shot learning and catching a glimpse of something bigger
As mentioned on my page dedicated to my project, it seems that our work has been done in parallel to another one. This other work has uncanny similarities to our own. I took note of this when reading the newsletter The Batch, specifically the issue published May 20, 2020.
My eyes caught the title “Small Data the Simple Way” (link to full study). This was a summary about a study on few-shot learning, the art of learning from limited data. Since this is more or less what I have been researching for the past semester I was curious to look at their work. Here is an excerpt from the summary:
How it works: The researchers used conventional supervised learning to train a network to classify images that represent 100 different classes, using 600 images of each class. Simple classifiers for each task had the same architecture and parameters up to the final hidden layer.
- After training, the network’s output layer was removed and the final hidden layer was used as a feature extractor.
- A logistic regression model used features from the extractor to learn from a small number of examples of a novel class.
- The researchers improved the system’s accuracy via knowledge distillation; that is, using an existing model to train a new one. The first feature extractor’s output fed a second, and the second learned to recreate the first’s output. They performed this operation repeatedly.
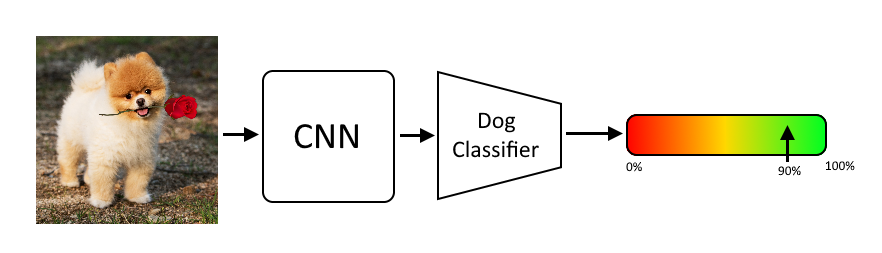
This is just so weirdly similar to my idea. Now, I had never heard of knowledge distillation before (I can not wait to learn more about it), but the rest is very similar. Compare our model pictured below, a model with a shared CNN and swappable classifiers, with the quote detailing how the other model works:
Why did I catch a glimpse of something bigger? I got closer than I ever imagined to something huge.